In this blog post, we described Spark SQL DATE and TIMESTAMP types. Since version 3.0, Spark switched from the hybrid calendar, which combines Julian and Gregorian calendars, to the Proleptic Gregorian calendar (see SPARK for more details). This allowed Spark to eliminate many issues such as we demonstrated earlier. For backward compatibility with previous versions, Spark still returns timestamps and dates in the hybrid calendar (java.sql.Date and java.sql.Timestamp) from the collect like actions.
To avoid calendar and time zone resolution issues when using the Java/Scala's collect actions, Java 8 API can be enabled via the SQL config spark.sql.datetime.java8API.enabled. Try it out today free on Databricks as part of our Databricks Runtime 7.0. The internal values don't contain information about the original time zone. Future operations over the parallelized dates and timestamps value will take into account only Spark SQL sessions time zone according to the TIMESTAMP WITH SESSION TIME ZONE type definition. Collect() is different from the show() action described in the previous section. Show() uses the session time zone while converting timestamps to strings, and collects the resulted strings on the driver.

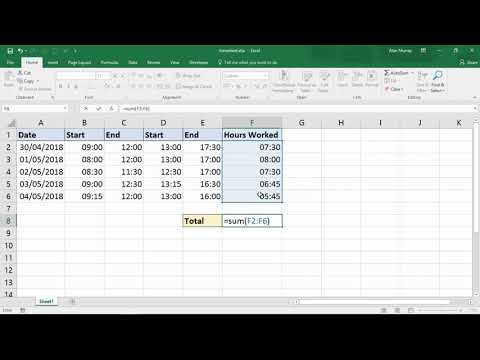
Calculating the time difference between two TIMESTAMP datatypes is much easier than the old DATE datatype. This means no more worries about how many seconds in a day and all those cumbersome calculations. And therefore the calculations for getting the weeks, days, hours, minutes, and seconds becomes a matter of picking out the number by using the SUBSTR function as can be seen in Listing G.

If the time zone is not specified, the default time zone is UTC. Now the conversions don't suffer from the calendar-related issues because Java 8 types and Spark SQL 3.0 are both based on the Proleptic Gregorian calendar. The collect() action doesn't depend on the default JVM time zone any more.

The timestamp conversions don't depend on time zone at all. Regarding to date conversion, it uses the session time zone from the SQL config spark.sql.session.timeZone. For example, let's look at a Dataset with DATE and TIMESTAMP columns, set the default JVM time zone to Europe/Moscow, but the session time zone to America/Los_Angeles. As the example demonstrates, Spark takes into account the specified time zones but adjusts all local timestamps to the session time zone. One of the main problems with the DATE datatype was its' inability to be granular enough to determine which event might have happened first in relation to another event.

Oracle has expanded on the DATE datatype and has given us the TIMESTAMP datatype which stores all the information that the DATE datatype stores, but also includes fractional seconds. This is only because when converting from the DATE datatype that does not have the fractional seconds it defaults to zeros and the display is defaulted to the default timestamp format . If you wanted to show the fractional seconds within a TIMESTAMP datatype, look at Listing E. In Listing E, we are only showing 3 place holders for the fractional seconds. PostgreSQL is a powerful database management system that allows you to perform various operations on your data. It has plenty of functions and operators to work with date & time columns, as well as literal strings. Sometimes you may need to add a specific amount of minutes, hours & months to your date/time value.

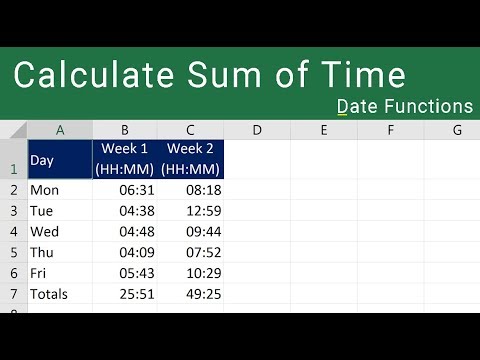
In this article, we will learn how to add minutes, hours & months to timestamp in PostgreSQL. Postgres date types are essential and valuable when storing date and timestamps in almost every table of a relational database. You need them for various purposes such as order insertion or when updating timestamp, purchases and sales orders, event details, customer and employee information and more. You can use multiple Postgres functions to convert a date type to the required time zone, format and specific information to simplify the extraction and analysis of your data. The java.time.Instant object can be converted to any local timestamp later independently from the global JVM time zone. This is one of the advantages of java.time.Instant over java.sql.Timestamp.
The former one requires changing the global JVM setting, which influences other timestamps on the same JVM. The NOW() date function returns the current timestamp in UTC . You can subtract intervals from NOW() to pull events that happened within the last hour, the last day, the last week, etc. The result of many date operations includes a fraction.

These fractions are also returned by Oracle built-in SQL functions for common operations on DATE data. For example, the built-in MONTHS_BETWEEN SQL function returns the number of months between two dates. The fractional portion of the result represents that portion of a 31-day month.
The time zone is stored as an offset from UTC or as a time zone region name. The data is available for display or calculations without additional processing. A TIMESTAMP WITH TIME ZONE column cannot be used as a primary key. If an index is created on a TIMESTAMP WITH TIME ZONE column, it becomes a function-based index. Although you cannot use a TIMESTAMP column as a partition key, you can extract the individual years, months, days, hours, and so on and partition based on those columns. See Partition Key Columns for more details on partitioning with date and time values.

In Impala 2.2.0 and higher, built-in functions that accept or return integers representing TIMESTAMP values use the BIGINT type for parameters and return values, rather than INT. This change lets the date and time functions avoid an overflow error that would otherwise occur on January 19th, 2038 (known as the "Year 2038 problem" or "Y2K38 problem"). This change affects the FROM_UNIXTIME() and UNIX_TIMESTAMP() functions. The first argument is the datetime/time to which we're adding time; this can be an expression that returns a time/datetime/timestamp value or the name of a time/datetime/timestamp column. In our example, we use the arrival_datetime column, which is of the datetime data type. This is the datatype that we are all too familiar with when we think about representing date and time values.

It has the ability to store the month, day, year, century, hours, minutes, and seconds. It is typically good for representing data for when something has happened or should happen in the future. The problem with the DATE datatype is its' granularity when trying to determine a time interval between two events when the events happen within a second of each other.

This issue is solved later in this article when we discuss the TIMESTAMP datatype. In order to represent the date stored in a more readable format, the TO_CHAR function has traditionally been wrapped around the date as in Listing A. As we did for dates, let's print the content of the ts DataFrame using the show() action. In a similar way, show() converts timestamps to strings but now it takes into account the session time zone defined by the SQL config spark.sql.session.timeZone. Date and time functions perform conversion, extraction, or manipulation operations on date and time data types and can return date and time information.

You can set the default session time zone with the ORA_SDTZ environment variable. When users retrieve TIMESTAMP WITH LOCAL TIME ZONE data, Oracle returns it in the users' session time zone. The session time zone also takes effect when a TIMESTAMP value is converted to the TIMESTAMP WITH TIME ZONE or TIMESTAMP WITH LOCAL TIME ZONE datatype. NEXT_DAY returns the date of the first weekday named by charthat is later than date.

The return type is always DATE, regardless of the datatype of date. The argument char must be a day of the week in the date language of your session, either the full name or the abbreviation. The minimum number of letters required is the number of letters in the abbreviated version. Any characters immediately following the valid abbreviation are ignored. The return value has the same hours, minutes, and seconds component as the argument date.

If you want to convert a DATE datatype to a TIMESTAMP datatype format, just use the CAST function. As you can see, there is a fractional seconds part of '.000000' on the end of this conversion. If you are moving a DATE datatype column from one table to a TIMESTAMP datatype column of another table, all you need to do is a INSERT SELECT FROM and Oracle will do the conversion for you.

What needs to be realized when doing the calculation is that when you do subtraction between dates, you get a number that represents the number of days. You should then multiply that number by the number of seconds in a day before you continue with calculations to determine the interval with which you are concerned. Check out Listing B for my solution on how to extract the individual time intervals for a subtraction of two dates. I am aware that the fractions could be reduced but I wanted to show all the numbers to emphasize the calculation. You can also use the EXTRACT() function in combination with an INTERVAL.

For example, below we specify the interval as 7 years 9 month 20 days 09 hours 12 minutes and 13 seconds. You can use the minus (-) operator to calculate the difference between two dates. For example, the query below returns the interval between the current timestamp and from the SalesOrders table.

This page documents functions to construct and manipulate date and time values in Rockset. Refer to the data types page for more information about the date and time data types. By default, we use the time zone from your web browser set by the operating system to display hours and minutes everywhere in our user interface.

You can change the default time zone that the user interface displays by adjusting theDefault Timezonesetting on thePreferencespage. This option overrides the time zone from your web browser, and changes how hours and minutes are displayed in the UI. But this is a personal setting, and does not change the time zone for anyone else in your organization. The example below shows making timestamps from Scala collections. In the first example, we construct a java.sql.Timestamp object from a string.
The valueOf method interprets the input strings as a local timestamp in the default JVM time zone which can be different from Spark's session time zone. If you need to construct instances of java.sql.Timestamp or java.sql.Date in specific time zone, we recommend to have a look at java.text.SimpleDateFormat or java.util.Calendar. In the following example, timestamp_expression has a time zone offset of +12.

The first column shows the timestamp_expression in UTC time. The second column shows the output of TIMESTAMP_TRUNC using weeks that start on Monday. Because the timestamp_expression falls on a Sunday in UTC, TIMESTAMP_TRUNCtruncates it to the preceding Monday. The third column shows the same function with the optional Time zone definitionargument 'Pacific/Auckland'.

Here the function truncates thetimestamp_expression using New Zealand Daylight Time, where it falls on a Monday. When you compare date and timestamp values, Oracle converts the data to the more precise datatype before doing the comparison. You can use NUMBER constants in arithmetic operations on date and timestamp values. Oracle internally converts timestamp values to date values before doing arithmetic operations on them with NUMBER constants.

This means that information about fractional seconds is lost during operations that include both date and timestamp values. Oracle interprets NUMBER constants in datetime and interval expressions as number of days. In addition, UNIX_TIMESTAMP() assumes that its argument is a datetime value in the session time zone. See Section 5.1.15, "MySQL Server Time Zone Support". DATE is the datatype that we are all familiar with when we think about representing date and time values.

The problem with the DATE datatype is its' granularity when trying to determine a time interval between two events when the events happen within a second of each other. Date and timestamps are helpful for data analysis and storing data for checking when an event actually took place. For example, when you have purchase and sales orders, monthly or quarterly earnings and more. Date formats vary across countries, therefore it can be a complicated task for those who are new todatabase managementand are working with date columns. The format or data type of the date column should always match the user's input. Additionally, you should convert the date format display per your user's requirements.

Now is the current timestamp or date at the session time zone. Within a single query it always produces the same result. It is possible to create one dimension for each individual timeframe or duration you want to include, instead of generating all of them in a single dimension_group. You can generally avoid creating individual dimensions, unless you want to change Looker's timeframe naming convention, or you have already pre-calculated time columns in your database. For more information, see the Dimension, filter, and parameter types documentation page. In this case, when Looker performs time zone conversions, errors can occur.

To avoid this, in the sql parameter of the dimension, you should explicitly cast the timestamp data to a timestamp type that does not do time zone conversion. For example, in the Snowflake dialect, you could use the TO_TIMESTAMP function to cast the timestamp data. This example shows the effect of adding 8 hours to the columns.

The time period includes a Daylight Saving Time boundary . The orderdate1 column is of TIMESTAMP datatype, which does not use Daylight Saving Time information and thus does not adjust for the change that took place in the 8-hour interval. The TIMESTAMP WITH TIME ZONE datatype does adjust for the change, so the orderdate2 column shows the time as one hour earlier than the time shown in the orderdate1 column.

To resolve these boundary cases, Oracle uses the TZR and TZD format elements. TZR represents the time zone region in datetime input strings. Examples are 'Australia/North', 'UTC', and 'Singapore'.

TZD represents an abbreviated form of the time zone region with Daylight Saving Time information. Examples are 'PST' for US/Pacific standard time and 'PDT' for US/Pacific daylight time. To see a list of valid values for the TZR and TZD format elements, query the TZNAME and TZABBREV columns of the V$TIMEZONE_NAMES dynamic performance view. Setting the session time zone does not affect the value returned by the SYSDATE and SYSTIMESTAMP SQL function.




No comments:
Post a Comment
Note: Only a member of this blog may post a comment.